Interesting Applications of GPT-3: Elicit
What this Post is About
A few months ago, I gained access to a new exciting tool called Elicit from Ought. Elicit is an AI research assistant that helps you answer questions "by making qualitative reasoning steps explicit and using language models to incrementally automate those steps."
Above, we can see Elicit's main page, where I am on the Task picker. (Though it's hidden here, there is a text prompt box below the task selector where you can type in a question, topic or sentence.)
You can watch Elicit screencasts on YouTube to get a sense of all the things it can do. It is impressive.
Here's a general overview of what Elicit can do:
You can see below a video of Elicit being used to help researchers search for papers on the topic of military applications of AI, something that the Center for Security and Emerging Technology (CSET) is interested in and has done great work on.
What Excites me about Tools like Elicit
Recent innovations in machine learning have helped us build models that deal with labeled data tasks, but how can we use these models to answer questions where we don't have a labeled dataset and are a bit more subjective? For example, could we have an AI where we can ask it questions like "How do I decide what career I should dedicate my life to?" or "My partner feels jealous about my career growth, what should I do?" It would be fantastic if we could have an AI that could answer these questions.
I'm particularly excited about how AI will help make knowledge accessible to everyone in a way that will guide humanity towards a better future. Though still in its early stages, AI has started showing signs of having the potential to revolutionize education, research, and even therapy.
One glimpse of this was in a Twitter thread where one of the employees at OpenAI said they used GPT-3 as a therapist and achieved a more profound breakthrough than they had ever had with a human therapist. Of course, we're not at the point where our models can be taken out of the labs yet. However, once our models become exceptional and robust (and we can make such services unbelievably cheap, accessible, and compatible with human values), the inequality of world-class services will likely change quickly.
Initial look into Elicit
For this blog post, I will focus on giving an overview of Elicit rather than going into the nitty-gritty. So, I'm not going to be too formal and will instead point to some of the things I find cool and give my thoughts.
Going back to AI for mental health, we can see here how Elicit is used to help do Positive Reframing of negative statements you tell it. The video below shows how they give Elicit prompts for Few-Shot Learning. If you simply ask GPT-3 a question without any prompts, we call it a "Zero-Shot" model. Once we give it one example (K=1), it becomes a "One-Shot" model. For more than one example (K=2+), we call it a "few-shot" model. The more examples we give, the more accurate it will be, but it can still provide great results with very few examples. As we saw in the original GPT-3 paper, as you increase K, GPT-3 can perform better than a model like BERT fine-tuned on a given task (scroll a bit to see a plot example from the paper). That is why it is helpful to add examples in Elicit.
Here's a chart showing GPT-3 performance on a Trivia task:
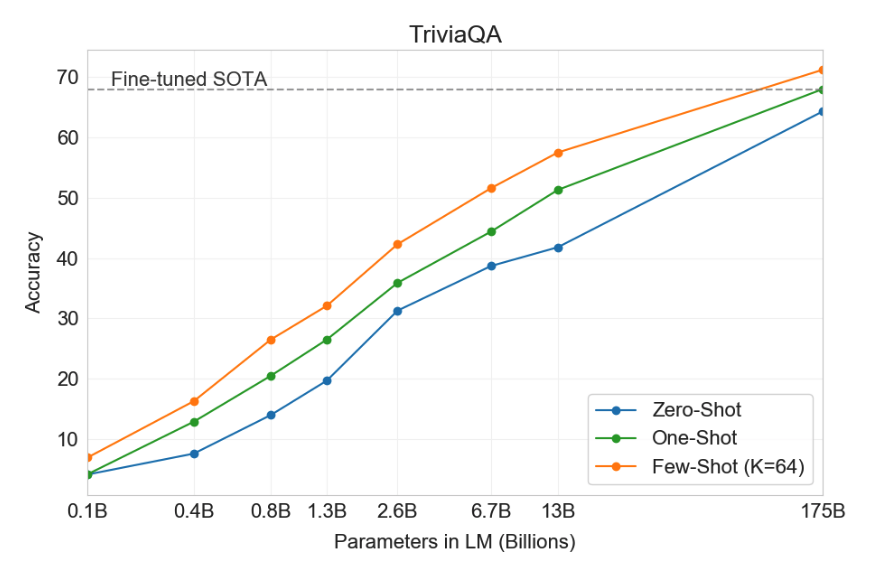
On TriviaQA GPT3's performance grows smoothly with model size, suggesting that language models continue to absorb knowledge as their capacity increases. One-shot and few-shot performance make significant gains over zero-shot behavior, matching and exceeding the performance of the SOTA fine-tuned open-domain model, RAG.
This is exciting and all, but I should note that this is not always the case, and you need to be aware when a fine-tuned model trained on full training data will be better in your situation. As we can see in a recent paper, GPT-3 does not mean the end of fine-tuned models.
We investigated the performance of two powerful transformer language models, i.e. GPT-3 and BioBERT, in few-shot settings on various biomedical NLP tasks. The experimental results showed that, to a great extent, both the models underperform a language model fine-tuned on the full training data. Although GPT-3 had already achieved near state-of-the-art results in few-shot knowledge transfer on open-domain NLP tasks, it could not perform as effectively as BioBERT, which is orders of magnitude smaller than GPT-3.
That said, GPT-3 was created to be as good as possible to a whole variety of tasks with no fine-tuning, and it did not fall short of that.
Creating a Task in Elicit
Here's a video of how to create your own task in Elicit so that you can mold it for your specific needs.
I won't go into the details here since the video is very comprehensive.
The Use of Stars in Elicit
You will notice by watching the videos that there are stars next to each output. Clicking on these stars helps the underlying GPT-3 model become better at generating new output. In other words, my understanding is that they use the user-selected stars as additional prompts to the model, thereby increase K and making the few-shot model more accurate for the user.
As you select stars, you can generate more output and get more of the kind of output you are looking for.
What if none of the outputs are what you are looking for? Well, you can go to the bottom of the outputs and add a custom result to help the model out. After a few of these, you should see better results.
I think this is incredibly cool, and it was implemented beautifully. A few months ago, I was working on a project and trying to label a dataset using zero-shot learning, but I wasn't too impressed with the output. It got me thinking about different ways to use these models to help us label data. Depending on what we are trying to do, there are a few approaches we could take. From using a library like Snorkel, implementing an active learning component (an introduction can be found here), using a fine-tuned model for our specific task, or, of course, use GPT-like models to label data. One exceptional example of using GPT-3 to label data can be found here:
What's awesome about this video is that Xavier Amatriain says that GPT-3 was better at creating labeled data for their models than anything they could have come up with themselves. Part of the reason is that GPT-3 could generate not only much more data but also much more diverse (nuanced variability) data.
So, you could create an active learning process along with GPT-3 to label the data, and as more quality data becomes available, you can even fine-tune a pre-trained model on that generated data (which is what Curai seems to be doing).
Creating a Search Task in Elicit
In this video, we can see how we can use investment data to create a search task. For example, we can imagine VCs using Elicit to search for companies they might be interested in investing in. There's also a "Composite" task type (Compose multiple task types together into one). We could imagine a VC firm could create a search task that answers questions about the companies and then consolidate the companies that meet specific criteria.
Using Elicit as a Researcher
As was alluded to earlier, Ought puts a lot of effort into helping researchers conduct research. This can range from:
- Finding the best papers in a given field
- Generating research questions
- Identifying the most important sentence in an abstract to help quickly answer whether the paper is relevant or not
- Finding research collaborators
- Explaining a concept very simply or in terms you would better understand (ex: explain this economics concept in computer science terms)
Here's a video that shows how to create a list of potential research collaborators quickly:
And here's a video where Elicit suggests which concepts you should focus on learning about to get a better understanding of a topic:
This is one of the best ways I've found to better understand a topic/field very quickly, at least to the point where you can have a conversation with other experts in the field. We can imagine that people who need to grasp many concepts can significantly benefit from this task in Elicit. For example, VCs trying to grasp new technologies, politicians trying to understand something like Cryptocurrency, or interdisciplinary researchers trying to connect multiple fields.
Into Forecasting?
Elicit has a feature called Elicit Forecast which is hidden from the main website, but they go into a bit of detail about how it works in the video below. For any aspiring superforecaster out there, this could be a great tool.
In the future, we can expect people will ask Elicit a question like, "Will we be able to finish project x on time?" and Elicit will give us its best guess. As time goes on, I'm sure a tool like Elicit will become an invaluable tool for forecasters and people like project managers who want to get a better idea of how long a project will take.
Building AI based on what we've Learned from Human Thinking
There are concepts like First Principles Thinking (FTP) that have allowed humans to take great leaps in innovation. However, FTP is hard! We know how great it can be, yet few people use it habitually. Of course, it's basically unsustainable to use for every little thing that we do. That's why even the people who use FTP end up using it only when tackling complex (many moving parts with feedback loops) or complicated (very difficult like building a rocket ship) problems. But what if we could lower the barrier to entry and sustainability for using FTP? What if we had an AI that allowed us to enter into an "FTP state of thinking" more often and with higher effectiveness? Perhaps we could accelerate the work of great innovators and help those who never really got into an FTP state of thinking. I can see Elicit helping in this direction.
But here's what the people at Ought are already working on: generating subquestions and searching for answers to those subquestions!
This mode of thinking was quite common when I was studying physics. And in fact, the physicist Enrico Fermi was known for, among many other things, using "Fermi Estimates" to make an educated guess about a question. Breaking down the main question into subquestions, he answered the main question by creating estimates for the subquestions and feeding that into the main question. This method is now commonly used in forecasting, and people will often run Monte Carlo simulations to get a guesstimate for each subquestion. I initially came across this idea more formally in the book How to Measure Anything by Douglas W. Hubbard.
Anyway, as we see in that video, Elicit can generate subquestions to what seems to be an impossible question to answer. At the moment, the search results to help users answer the subquestions will be linked to documents that may contain the answer. I believe they have made some progress since then, but I can see this going further in the future. For example, you could extract the text from a database of documents and use a model to actually answer the subquestion for the user and point to where exactly it found the answer in the document. (This may already be possible!)
In other words, you could have an open-ended question like "How can we strengthen the US AI workforce?" and Elicit could generate all the relevant subquestions and answer them! Beyond that, it could potentially help answer questions like "How many professional piano tuners are there in Chicago?" by answering a series of subquestions like "What is the population of Chicago?" and "How many people in Chicago own a piano?"
I think it could eventually end up doing a great job of answering questions like "By 2070, how many climate refugees will there be in the US?" by giving a nice probability distribution guesstimate with specific reasons for the output described.
Closing Thoughts
I've worked in government for the past four years, and many things excite me about Elicit, things that I thought of building myself. So I'm glad someone is building a tool like this.
As they write on their website, I can see it being applied in government policy (Senators could become better at asking questions and could get caught up to speed on issues much more effectively than the current approach), but I can also see it working in strategic foresight teams like Policy Horizons Canada or in regulatory bodies (like the Canada Energy Regulator, my old employer) who have to dig into tons of PDFs to find the right information and make sure the company is compliant with the law. Note: if you are interested about Strategic Foresight, I give an introduction here.
One of the things I am the most excited about is creating a second brain with a tool like Elicit. Sure we can use Roam Research to connect our thoughts, and we can even load tons of text in Roam Research. Still, I think Semantic Search with Elicit could be much more powerful by simply having it point to or answer questions we have on a specific topic after loading 100k documents on that topic. (And actually, I'm pretty sure this is already possible in Elicit, so I'll update this if I find out if it is!)
Member discussion