Notes on Cicero
Top Diplomacy players focus on gigabrain strategies rather than deception. Backstab someone once and they'll still feel you are untrustworthy across tournaments. It's mostly optimal to be honest.
Link to YouTube explanation by Yannic Kilcher:
Link to paper (sharing on GDrive since it's behind a paywall on Science): https://drive.google.com/file/d/1PIwThxbTppVkxY0zQ_ua9pr6vcWTQ56-/view?usp=share_link
Top Diplomacy players seem to focus on gigabrain strategies rather than deception
Diplomacy players will no longer want to collaborate with you if you backstab them once. This is so pervasive they'll still feel you are untrustworthy across tournaments. Therefore, it's mostly optimal to be honest and just focus on gigabrain strategies. That said, a smarter agent could do stuff like saying specific phrasing to make one player mad at another player and then tilt really hard. Wording could certainly play a role in dominating other players.
Why did the model "backstab" the human? How is it coming up and using plans?
It seems that the model is coming up with a plan at one point and time and honestly telling the user that's the plan they have. The plan can predict several steps ahead. The thing is, the model can decide to change that plan on the very next turn, which sometimes leads to what we would consider as backstabbing.
They only 'enforce' consistency (with a classifier) when comparing what the model intends to do in the next action and what its message implies it will do. If the classifier notices that the intent from the reasoning engine and the implied intent from the message it's about to send diverge, the system will avoid sending that message. However, as I understand it, they are not penalizing the model for developing a new plan at t+1. This is what leads to the model making an honest deal on one turn and then backstabbing that person on the next turn. It just decided to change plans.
At no point is the model "lying"; it's just updating its plan. Cicero will straight up tell you that it's going to backstab you if that is part of its plan because the model is forced to communicate its intent 'honestly.'
Current interpretability techniques and future systems
At the moment, it seems that the main worry for interpretability is that the model has some kind of deceptive module inside of it. This is certainly an issue worth investigating for future powerful AI. What might not be clear is what we should do if deception is some emergent behaviour part of a larger system we place a language model within.
Future AI systems will likely have language models as a central component. We might think that if we do interpretability on a model's internals and find no deception, we're good. But once we place that model in a bigger system, it may lead to deceptive behaviour. For Cicero, that looks like the model choosing one thing at turn 1 and then doing something different at turn 2.
In the case of Cicero, the language model is only translating the intent of the strategic reasoning engine; it is not coming up with plans. However, future AI systems will likely have language models as more of a central component, and we might think that if we just do interpretability on that model's internals and we find no deception, it means we're good. However, this might not be the case. It may be that once we place that model in a bigger system, it leads to some form of deceptive behaviour. For Cicero, that looks like the model choosing one thing at turn 1 and then doing something different from the first intended plan at turn 2.
The model is not including how specific messages will maximize EV
The language model essentially translates the intent from the reasoning engine into chat messages. It is not, however, modeling how it could phrase things to deceptively gain someone's trust, how asking questions would impact play, etc.
Clarification about the dialogue model
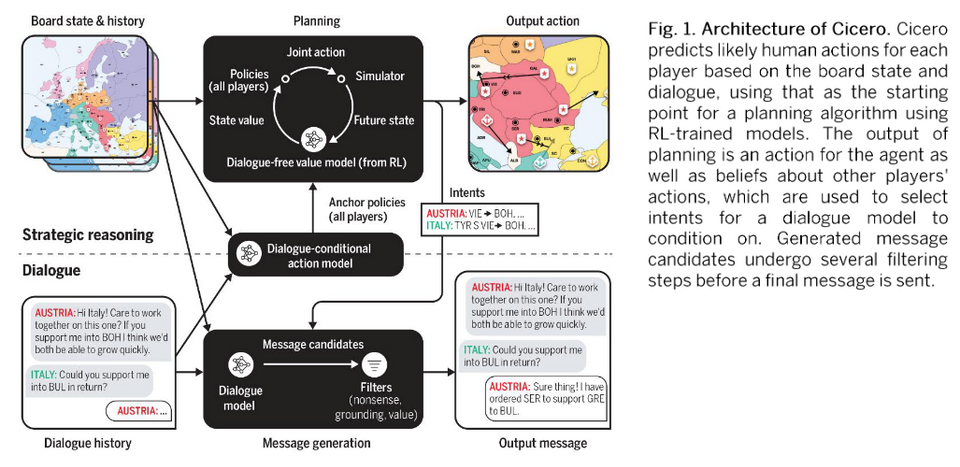
Note that the dialogue model feeds into the strategic reasoning engine to enforce human-like actions based on the previous conversations. If they don't do this, the players will think something like, "no human plays like this," and this may be potentially bad (not clear to me as exactly why; maybe increases the likelihood of being exploited?).
Should we be worried?
Eh, I'd be a lot more worried if the model was a GPT-N model that can come up with long-term plans that uses language to manipulate players into certain actions. I expect a model like this to be even more capable at winning, but straight up optimize for galaxy-brain strategies that focus on manipulating and tilting players. The problem arises when people build a Cicero-like AI with a powerful LLM as the core, tack on some safety filters, and assume it's safe. Either way, I would certainly not use any of these models to make high-stakes decisions.
Comments here: https://www.lesswrong.com/posts/jXjeYYPXipAtA2zmj/jacquesthibs-s-shortform?commentId=m9cv8tRoaNByw9Ck5
Member discussion