Detail about factual knowledge in Transformers
This post is currently in the Appendix of a much longer post I'm currently editing and waiting for feedback.
In the ROME paper, when you prompt the language model with "The Eiffel Tower is located in Paris", you have the following:
- Subject token(s): The Eiffel Tower
- Relationship: is located in
- Object: Paris
Once a model has seen a subject token(s) (e.g. Eiffel Tower), it will retrieve a whole bunch of factual knowledge (not just one thing since it doesn’t know you will ask for something like location after the subject token) from the MLPs and 'write' into to the residual stream for the attention modules at the final token to look at the context, aggregate and retrieve the correct information.
In other words, if we take the "The Eiffel Tower is located in", the model will write different information about the Eiffel Tower into the residual stream once it gets to the layers with "factual" information (early-middle layers). At this point, the model hasn't seen "is located in" so it doesn't actually know that you are going to ask for the location. For this reason, it will write more than just the location of the Eiffel Tower into the residual stream. Once you are at the point of predicting the location (at the final token, "in"), the model will aggregate the surrounding context and pull the location information that was 'written' into the residual stream via the MLPs with the most causal effect.
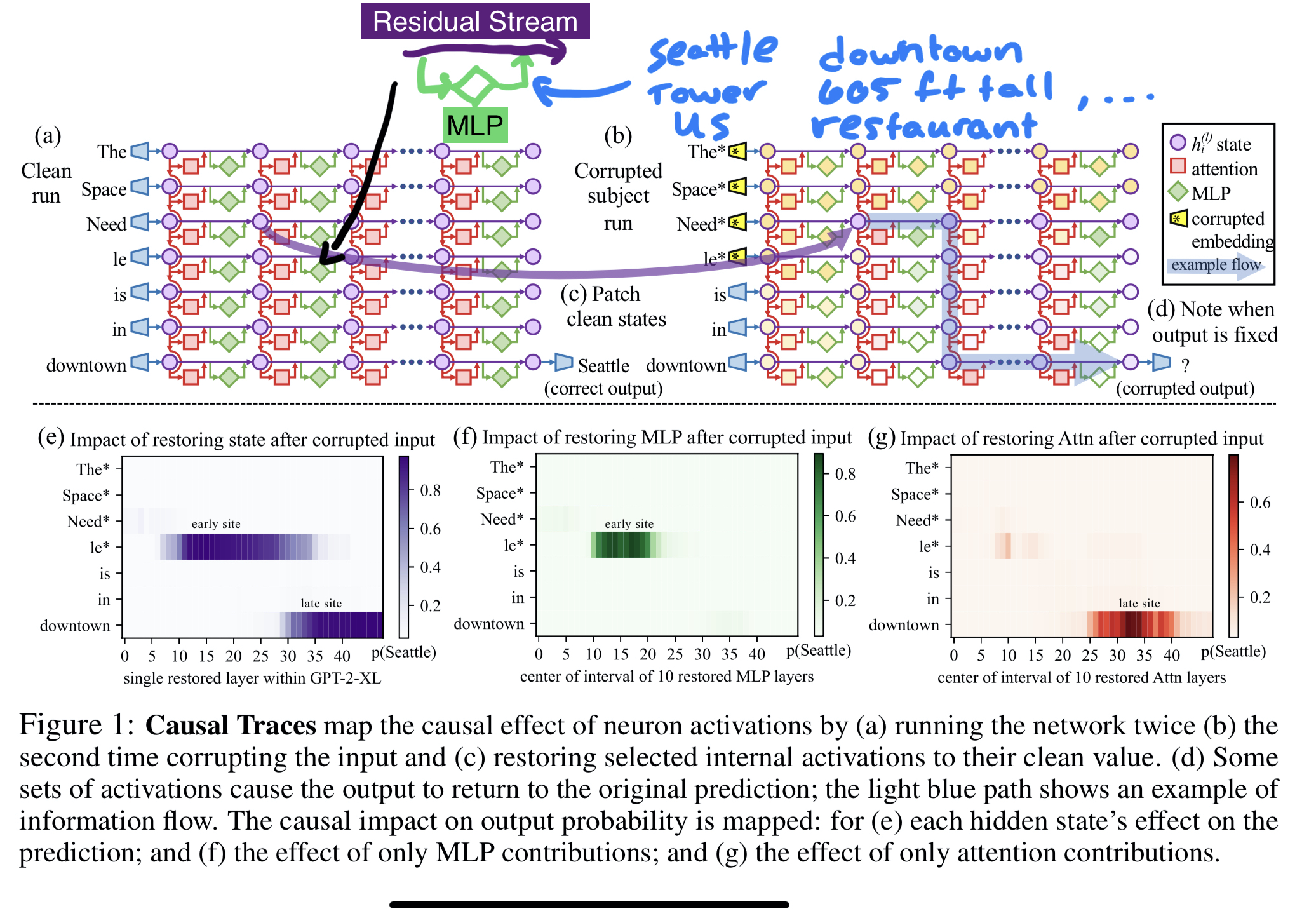
What is stored in the MLP is not the relationship between the facts. This is obvious because the relationship is coming after the subject tokens. In other words, as we said before, the MLPs are retrieving a bunch of factual knowledge, and then the attention modules are picking the correct (forgive the handwavy description) fact given what was retrieved and the relationship that is being asked of it.
My guess is that you could probably take what is being 'written' into the residual stream and directly predict properties of the subject token from the output of the layers with the most causal effect to predict a fact.
Thoughts and corrections are welcome on LessWrong.
Get new posts in your inbox
I write about AI safety, AI security, and the future we need to steer towards.
Member discussion